Amazon Redshift is a cloud-based data warehouse solution provided by Amazon and the group recently released a novel sorting technique – Interleaved sorting.
In order to understand how it differs from the conventional database sorting, let us start our discussion by going back to the concepts we already know and then gradually transition to this new concept. This will help to put things in perspective.
So, think of an address book. What is it that makes searching for a particular contact name fast? It’s because we save the names alphabetically. They are sorted. Simple, right?!
Now, if instead of name, I want to search by email id, would the search still be as fast as before? The answer is no unless you bring in the concept of secondary index [1]. One would have to look through every record until you find the required one. Drawing an analogy with databases, you can compare this effort of searching with the number of disk blocks that needs to be accessed.
In databases, reducing I/O (in other words, the number of disk blocks read/write operations) is a critical and dominant factor affecting query performance.
The concept of interleaved sorting is based on reducing the average number of disk block access in columnar databases[2] in a situation where you have multiple queries having different query filter patterns.
If you are not familiar with columnar databases, the following example in Figure 1 can help in explaining it pictorially as well. Briefly, they follow the storage style where values of individual columns from all records are stored together. Conventional database systems follow a row-oriented approach where entire record containing a bunch of columns is stored together.
Considering columnar databases for the rest of the article, there still exists two solutions for sorting when you have multiple queries with different query patterns. These are defining: a) compound sort keys, or (b) interleaved sort
Keeping this idea in mind, let us consider the following example to understand the concept of interleaved sorting.

Figure 1. Data Organization sorted by columns – cust_id and page_id [3]
Figure 1 shows four data blocks depicted by the colored rectangles. The notation [1,1] refers to customer and page with their respective IDs 1. Data is stored on disk sorted by customer ID first and then for the same customer id, it is organized further based on page ID. In other words, we have a compound sort key (cust_id, page_id).
Consider a query, Query 1 where one wishes to pull all page IDs for a particular customer. It can be clearly seen from Figure 1 that this would require one block access.
Further consider having another query, Query 2 where one wishes to retrieve IDs of all customers who accessed a specific page. Now, this would require four block accesses.
What we just discussed above is not only a difference in the number of disk blocks accessed but also an example of two queries having different query patterns. Query 1 had filter predicate on cust_id while Query 2 filters data based on page_id. The above example shows how our compound sort pattern is unable to optimize two queries at the same time (one vs. four block accesses)
Alternatively, notice the organization style in Figure 2 below.
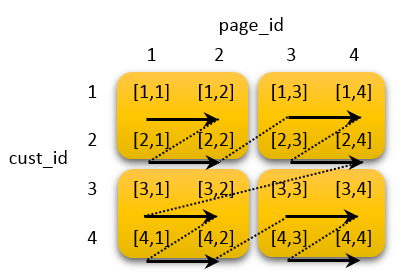
Figure 2: Data stored in an interleaved manner [3]
Regardless of whether data is retrieved based on cust_id or page_id, the number of block accesses are constant (two) in both cases. In other words, although Query 1 performance has degraded compared to when we had a compound sort key (two vs. one block access), but overall performance of the system that contains both Query 1 and 2 notices a gain.
The upshot becomes that interleaved sort keys are a preferable solution over compound sort keys when one has multiple queries reflecting different query patterns (different filter predicates). But there’s a caveat there. Even with a system having multiple query patterns, there are occasions where compound key is a favourable solution as discussed below.
Use-cases where compound keys emerge as a winner
1. A system which although consists of multiple queries with different filter conditions but the columns are always the same. As an example, assume that you have table with four columns: date, order_id, cust_id, location and there is a set of four queries defined with filter predicates as follows:
Q1: date, order_id, location
Q2: date, cust_id, order_id
Q3: date, order_id, cust_id (notice that order of columns in the filter pattern does not make any difference)
Q4: date
Compound sort key (date, order_id, cust_id) would be preferred choice over interleaved keys in such a case since it favors leading columns and we see that they are always present in all four of our queries.
Compare this to interleaved sort key (date, order_id, cust_id). The concept places equal importance to all three columns and thus Q4 in the query set above will show degraded performance.
2. If the data in the sorted table is constantly getting updated (insertions or deletions), then interleaved sorting incurs additional overhead since it often requires a lot of reshuffling and arrangement of data. This comes back to the point that data is organized based on a combination of columns simultaneously.
Thus there are trade-offs between compound and interleaved sorting. The decision on which one to use should depend on the specific use case and the nature of queries.
References
[1] https://docs.oracle.com/cd/E17275_01/html/programmer_reference/am_second.html
[2] https://en.wikipedia.org/wiki/Column-oriented_DBMS
[3] https://aws.amazon.com/blogs/aws/quickly-filter-data-in-amazon-redshift-using-interleaved-sorting
Additional Resource
[4] http://docs.aws.amazon.com/redshift/latest/dg/t_Sorting_data.html